
If you would notice this site’s front page, I’ve now replaced a bunch of parts of the side-bar (right side of the homepage) with some social feeds of networks I’m active on. This was an unintended effect of creating a caching proxy for work.
A proxy is a script that pulls data from another domain and outputs the data as is. It may seem silly; to require something to simply mirror the data of another site, when you can simply pull the data from the source itself. Logically, this is true, but in the intertubes, nothing is really simple.
You have to wrestle with domain implementation policies, wherein certain stuff simply doesn’t work because the application, browser, server won’t allow it as a matter of security.
Flash as an example, can be annoyingly strict about pulling data from a different domain. If you build and test your app locally there’s no problem, but once you upload that and run it, the same exact algorithm may or may not work depending on the policies of both the plugin and sometimes even the server itself.
A proxy placed in your localhost solves this by ensuring that the data your “application” is accessing comes from the same domain.
Now a caching proxy is something more; just like with the concept of caching in general it allows a feed to be pulled from the source via the proxy, but then it’s written to a file locally, and have an expiration on it. As long as it’s not “expired”, then the proxy will simply re-use the file it had generated instead of pulling the feed from the source for a set period of time.
This is extremely useful (and in my case, the reason why I made it) when dealing with rate-limited stuff. All social networks have their own rate limitations; if a user/application is polling their APIs too often, they will block access temporarily to prevent their servers from being overloaded with requests (similar to, if not tantamount to a DoS attack)
Practical Example
So as an example, let’s say this site is a high traffic site, where hundreds of visitors visit it per minute. Let’s also assume I have the proper infrastructure to handle the traffic.
Now my social feed on the side polls the various social networks, and I’ve implemented it via JQuery – so it’s kinda realtime when you load it. Meaning whenever a person visits the site, it will load the page, then run the JQuery script that then pulls the required feeds from the different social networks. As soon as that’s complete, it then loads them into their respective slots.
Now imagine that happening hundreds of times per minute. Twitter as an example is one of the stricter services to work with; and has a rate limit of about 15 API calls every 15 mintues 1 Or roughly one call per minute. Call more often than that, it will block you [temporarily]. No need for advanced math to know your site will be polling Twitter’s servers more than once per minute. Probably within the first few seconds, you’ve already went overboard.
With a cached proxy, you can easily solve that conundrum. You can set it to expire every minute – the first user to “trigger” the proxy will essentially be the first call to Twitter’s server, it will then store a cached version of that feed locally in your server. All requests henceforth will then be pulling from that cached file instead of Twitter’s servers. Until one minute’s up, then another user will eventually trigger the proxy when the cache has expired – only then will it pull the feed from Twitter’s server and “update” your local copy… and so on and so forth.
If you do the math, regardless of how many visitors your site has, you’re just polling Twitter’s server once every minute. To be on the safe side, you could extend the expiration far longer say every 5 to 10 mintues. That way you’d be sure you’ll be in the clear 🙂
The Proxy Script
http://www.nargalzius.com/downloads/proxy/proxy.phpSo first, may I invite you to visit that link to see what it does. You should see this:
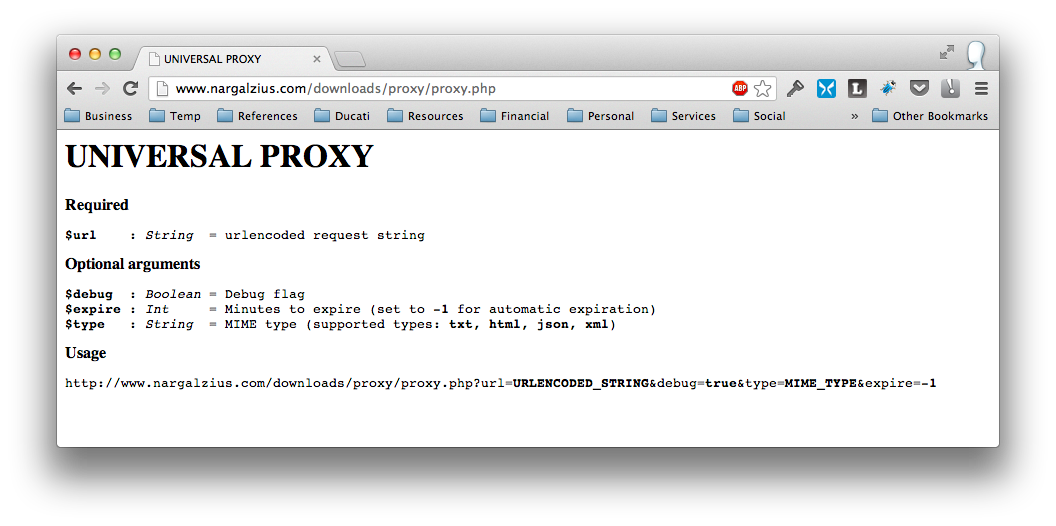
As you have observed, when you load up the proxy page without any arguments, it will just show you a quick guide on how to use it. The url listed at the bottom is a sample of a string using all optional arguments. But to get things going we only need a value for the url attribute. So essentially what we need would be this:
http://www.nargalzius.com/downloads/proxy/proxy.php?url=URLENCODED_STRING
The Feed We Want to Pull
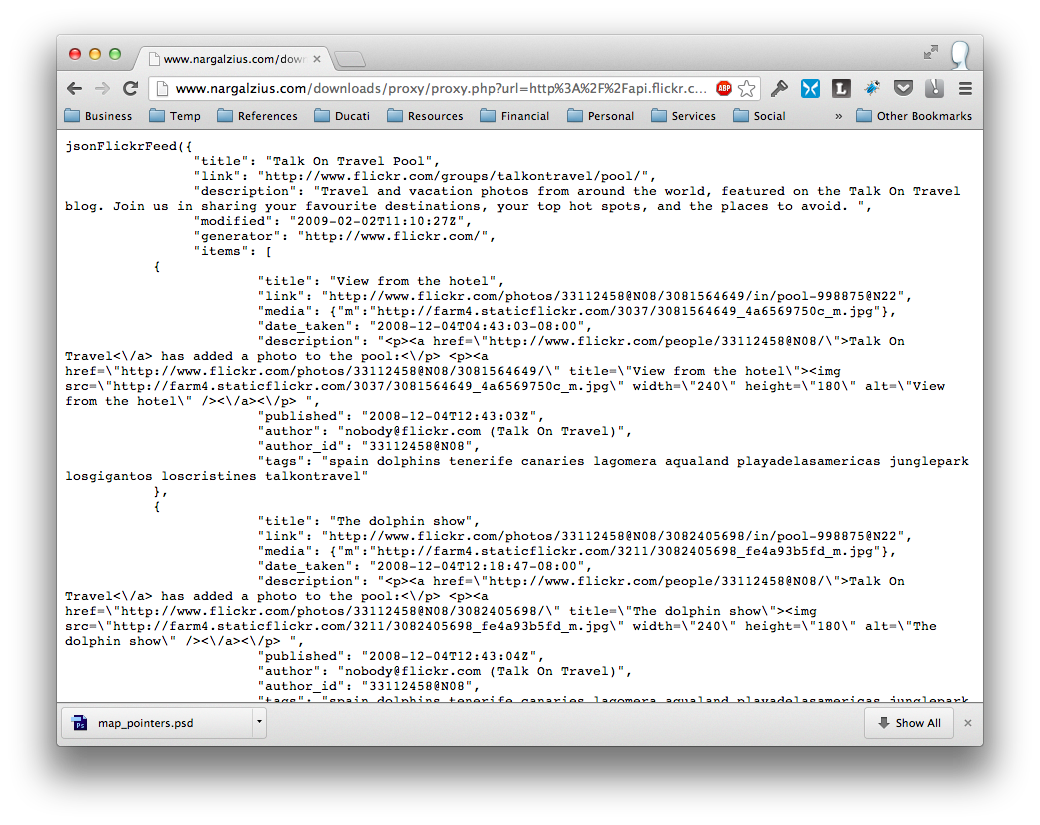
So I searched some tutorials to find some random feed that works (I wouldn’t want to be giving off my own feeds, now wouldn’t I?) and here’s what I found: A Flickr feed of some group called “Talk on Travel”
http://api.flickr.com/services/feeds/groups_pool.gne?id=998875@N22&lang=en-us&format=json
The feed url above basically pulls off a JSON feed for that group. Your mileage may vary (YMMV) depending on your browser, but when you click on the link you should see something similar to this:
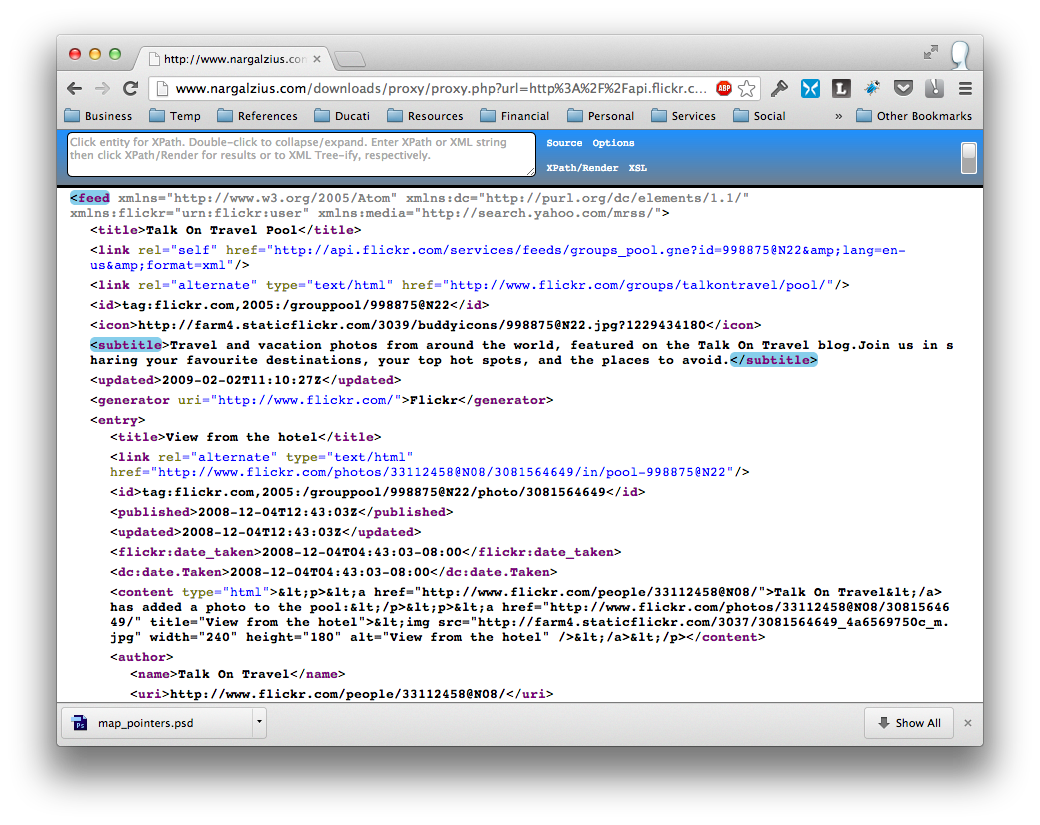
Luckily, Flickr has a very robust system of feed generation, so we can also pull the same feed in XML format, the url is as follows:
http://api.flickr.com/services/feeds/groups_pool.gne?id=998875@N22&lang=en-us&format=xml
Again YMMV – but you should see something like this.
Now those are examples of the raw feeds. Since we’ve already covered earlier why we would ideally use proxies, lets just go on ahead and take one of the example feeds and use it with my proxy. Let’s take the XML one.
Now we CANNOT just plug it into the proxy as is like so:
http://www.nargalzius.com/downloads/proxy/proxy.php?url=http://api.flickr.com/services/feeds/groups_pool.gne?id=998875@N22&lang=en-us&format=xml
That’s just might give us all sorts of browser/server parsing problems. The responsible thing to do is to “sanitize” to a safe format that’s friendly to any browser’s addressbar.
Multiple languages have functions that do this, but for the purposes of this “tutorial” let’s just use some url-encoding web service
So we take that url, put it into the url-encoder, encode it, and you get this:
http%3A%2F%2Fapi.flickr.com%2Fservices%2Ffeeds%2Fgroups_pool.gne%3Fid%3D998875%40N22%26lang%3Den-us%26format%3Dxml
Now we can use it with the proxy:
http://www.nargalzius.com/downloads/proxy/proxy.php?url=http%3A%2F%2Fapi.flickr.com%2Fservices%2Ffeeds%2Fgroups_pool.gne%3Fid%3D998875%40N22%26lang%3Den-us%26format%3Dxml
Now, if you visit that url, you should see something like this:

Success! You have loaded the feed and cached it locally on your server through the proxy 🙂
Optional Parameters
MIME Type
Now if you compare the original feed to the proxied feed, you’ll notice it’s exactly the same data, but for some reason it’s not displaying the same way. Something was lost in translation. Data-wise, this is no issue, you can use the data as you normally would without incident.
However when debugging or trying to craft your parsing algorithm, it does help to retain the legibility. That’s what the type attribute is for. Simply append the argument like so to force the MIME type into the :
http://www.nargalzius.com/downloads/proxy/proxy.php?url=http%3A%2F%2Fapi.flickr.com%2Fservices%2Ffeeds%2Fgroups_pool.gne%3Fid%3D998875%40N22%26lang%3Den-us%26format%3Dxml&type=xml
Load it up and viola!
I think the reason for the loss of header information is because the proxy always reads from a written generic .cache file. Meaning even when you first run the proxy, it will first take the feed data, then write it to the /cache directory, then loads it and displays it – so technically you’re never really loading the original feed directly in a sense. I guess when it does that, it basically just reads the local file (headers and all) as a plain generic file with no specific MIME type. Honestly it’s not that big of an issue for me to care about so it is what it is 🙂
Expire
Again we’re talking about cached proxies. The expire attribute allows a person to set how long before it decides to “re-write” the cached file with the most recent version of the file it’s caching.
When the attribute isn’t present, it defaults to 10 minutes I think. Which means whenever you load/reload the proxy, it will be faster since you’re pulling a static [cached] file. It wouldn’t matter if you refresh 30 or 30,000 times under 10 minutes, it wouldn’t matter – the source will only be pulled once, until it detects that it’s time for a refresh/re-write, then it will re-pull the data from the source.
If you set the expire value to -1 it will set the proxy to constantly refresh – so whenever you load it, it will always pull from the source and re-write the local cache file.
Sufficed to say if you forget to set this to a decent interval and pull a feed from a rate-limited site too often… you’re gonna have a bad time 😉
I also put in a failsafe wherein if the cache file exists, and the feed tries to refresh, but ends up with an error, it will just use the existing “working state” and double the expiration time – so it prevents from overwriting your cache with a malformed feed (in the event of an error)
Debug
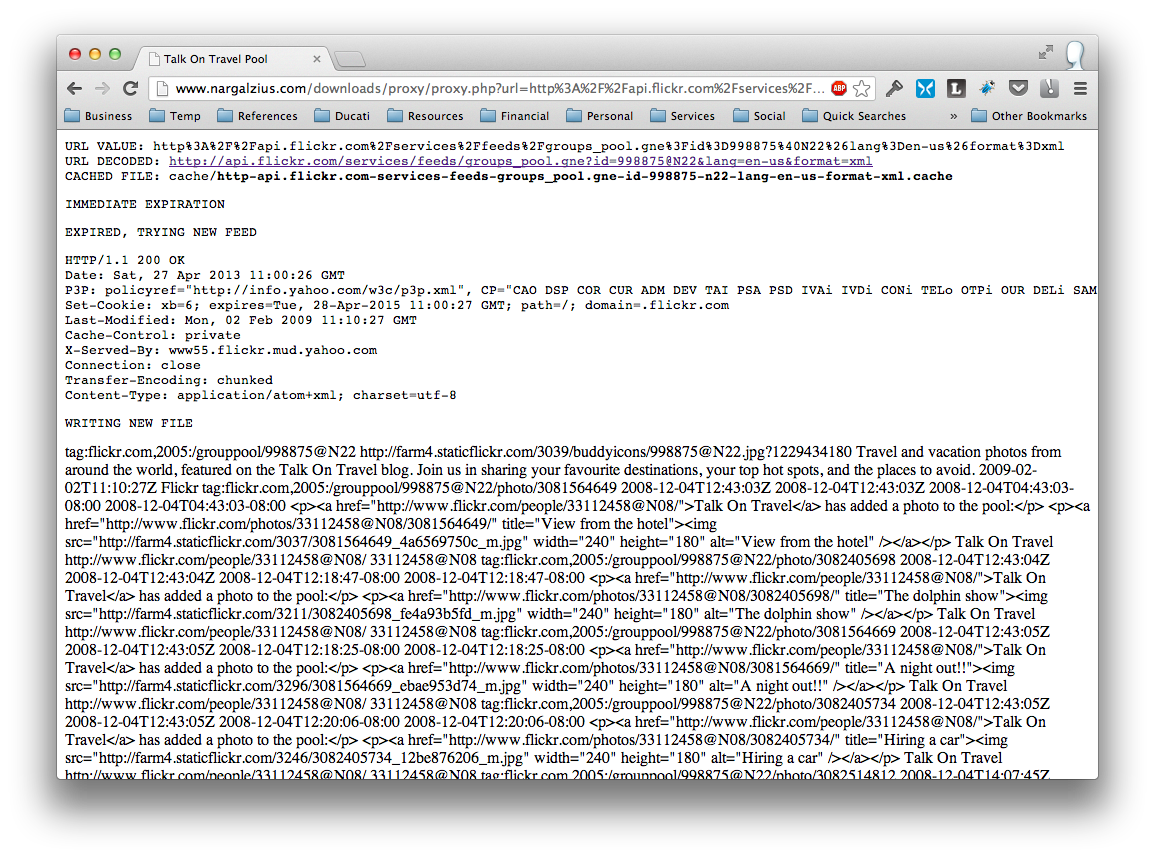
Pretty self-explanatory. This is meant to check on various stuff. Just add the debug attribute and set it to true like so:
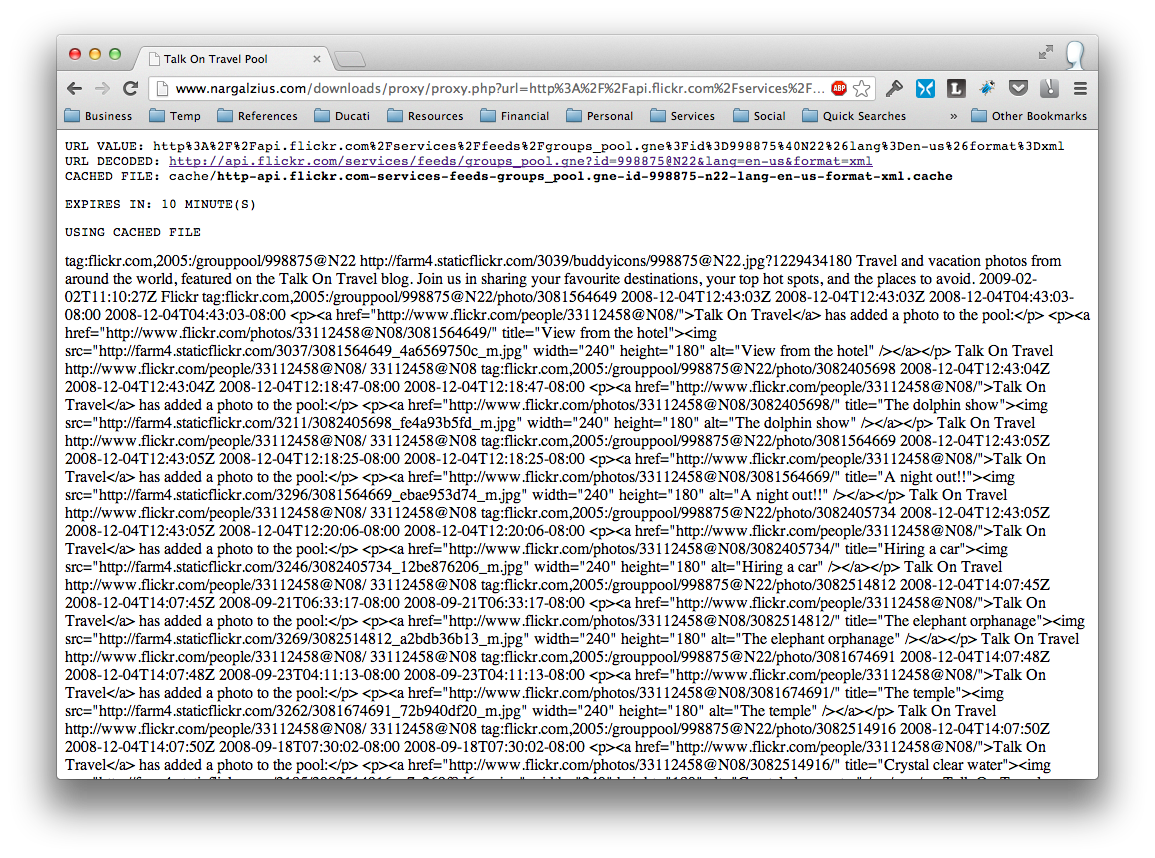
In the picture above you can immediately see useful information like:
- The url encoded
urlvalue being passed to the proxy. - The same url string decoded back to a proper url – so you can practically visit the site and check if it’s actually pointing to the right feed.
- The filename of the cached file it’s writing to / pulling from.
- The expiration time set
- If it’s using a cached file or if it’s generating a new one. Here’s what it looks like when you force it to expire
- A dump of the actual data below.
{kind=link}
This obviously bypasses the all the MIME shit, since it’s purpose is to just see what the hell the proxy is doing. This is a perfect way to test other optional arguments to just see if the proxy is recognizing the flags correctly.
Bugs
There are two bugs that I’m aware of:
First is that it may throw an error whenever it generates a cached feed for the first time. This seems to depend on the server environment. When I try it locally via MAMP, it just does it’s thing with no issues, but when I do it in nargalzius.com, it does make that error. Again, YMMV.
{kind=link}
It’s worth re-stating that this only happens (if ever it happens, that is) the very first time you generate a feed, 2 The reason why the sample feeds weren’t throwing errors was because the files already exist. If you want to try it, try adding some variables in the SOURCE url (source, meaning the one you plan to urlencode) and despite the error, it does successfully write the file. You can actually just press refresh and it will work henceforth. It doesn’t affect the over-writing procedure. Meaning once it has a file on there, you don’t have to worry about it throwing another error when it tries to re-write it.
UPDATE 2013.04.27: I’ve suppressed the warning/errors so I think i’ve just solved this issue – but I’m leaving the disclaimer/bug above in case it still persists.
Second bug is in the debug mode, sometimes when you set it in debug and have it expire immediately, even if you set it back to a timed interval it would continue to expire immediately. This is usually solved when you just disable debug load it, then enable it again.
It also may help when you make sure that the expire attribute is not set to auto-expire (-1) when you first get into debug mode. Once you’re in, and you change it to auto-expire and back, it seems to work.
Download & Instructions
This comes with no warranty, and you can modify it to suit your own needs.
Download it here
The only thing you have to do is make sure you have folder named ‘cache’ (with proper write permissions) wherever you put the proxy.php file on. Dead simple.
UPDATE 2013.04.30
This proxy is best used for its flexibility of making url-based unauthenticated 3 You can obviously also use rudimentary authenticated calls provided the access tokens can be put inline with the URL calls – since you just have to set the the url value appropriately and see the changes right away.
However, if you intend to use authenticated calls – and want to protect your codes/tokens 4 Especially_ using JavaScript where the calls are essentially in plaintext – it would be advisable to create a separate server-side file (e.g. PHP) file containing the authentication token/codes and the final url to be called. You can simply point the proxy to that file instead.
That way, the “call” will go through two steps; the new file will be the actual [authenticated] “proxy,” and our [original] proxy will be relegated to a mere caching service.
Notes
| ⇡1 | Or roughly one call per minute. Call more often than that, it will block you [temporarily]. |
|---|---|
| ⇡2 | The reason why the sample feeds weren’t throwing errors was because the files already exist. If you want to try it, try adding some variables in the SOURCE url (source, meaning the one you plan to urlencode) |
| ⇡3 | You can obviously also use rudimentary authenticated calls provided the access tokens can be put inline with the URL |
| ⇡4 | Especially_ using JavaScript where the calls are essentially in plaintext |